In this story, we will explore how to write a simple web-based chat app in Python using LangChain, ChromaDB, ChatGPT 3.5 and Streamlit.
The chat-based app will have its own knowledge base, i.e. it will have its own context. The context will be about Onepoint Consulting Ltd, the company the author of this blog is working for.
The chat app will allow users to query information about Onepoint Consulting Ltd. Here are a few examples of interactions with the chat app:
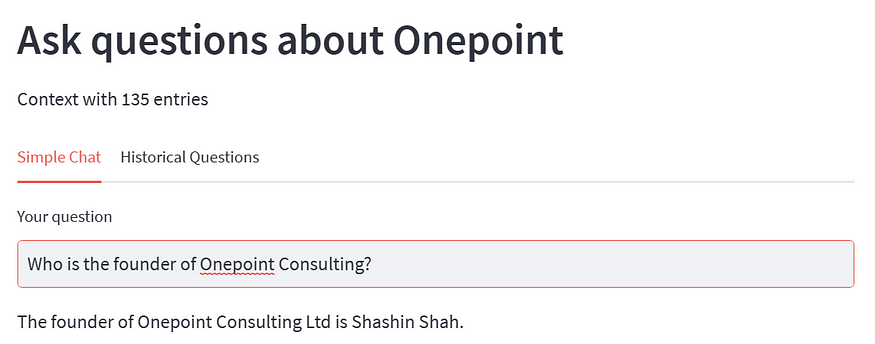


The techniques described in this blog allow you to create context based chat apps about any subject of your choice.
Chat App Components
A context-based chat app works internally with two major components:
A vector database is a newer type of database which operates with vectors (numerical lists) to represent data and is excellent for similarity searches. This is how Microsoft knowledge base defines what a vector database is:
“A vector database is a type of database that stores data as high-dimensional vectors, which are mathematical representations of features or attributes. Each vector has a certain number of dimensions, which can range from tens to thousands, depending on the complexity and granularity of the data.”
The large language model (LLM) is used to process the question with a context produced by the vector database.
Chat App Workflows
The chat app has two workflows:
- Vector DB Creation
- Chat Workflow
The Vector DB Creation workflow could be represented as BPMN:
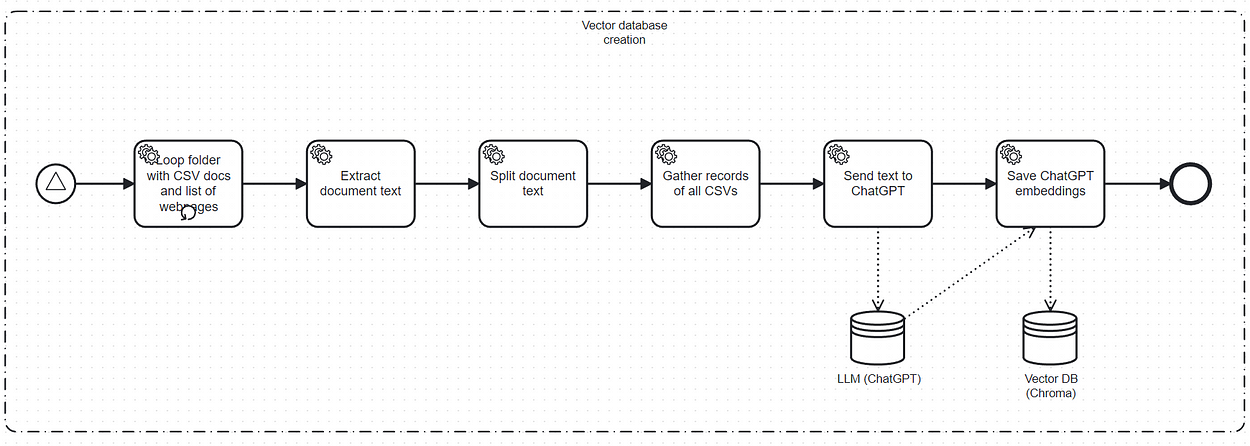
This Vector DB Creation describes what happens when you start the chat application in the background. The goal of this workflow is to generate the ChatGPT embeddings with ChromaDB.
It performs the following steps:
- Collect the CSV files in a specified folder and some web pages
- Extract the text of each CSV file
- Create a list of text records for the CSV file
- Gather all records of all CSV files in a list
- Send the gathered text list to ChatGPT to collect the corresponding embeddings
- Save the ChatGPT embeddings in memory and eventually on disk using ChromaDB.
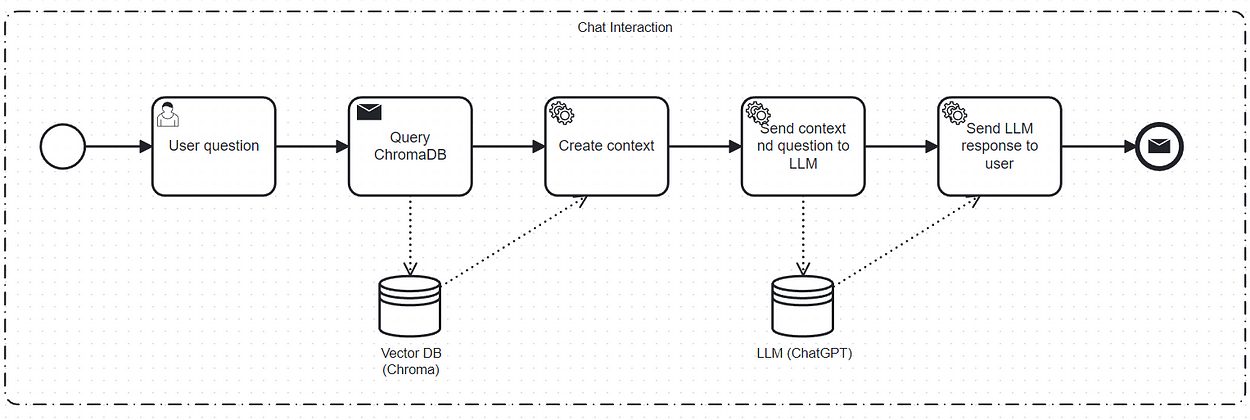
The Chat Workflow describes what happens when the user asks a question on the user interface:
- The user writes a question and hits the “Enter” button.
- A similarity search query is fired against the vector database.
- The query to the vector database returns a specific number of records (the most similar ones to the question)
- These records are combined with the question and sent to the LLM.
- The LLM then replies to the user and the response is displayed on the UI.
Pre-requisites
We create a Anaconda environment with Python 10 using the following libraries:
langchain==0.0.215
python-dotenv==1.0.0
streamlit==1.23.1
openai==0.27.8
chromadb==0.3.26
tiktoken==0.4.0Implementation
The implementation of the chat engine can be found in:
GitHub - gilfernandes/onepoint_chat: Onepoint Langchain Based Mini Chat App
Onepoint Langchain Based Mini Chat App. Contribute to gilfernandes/onepoint_chat development by creating an account on…
There is a single file with the whole code:
onepoint_chat/chat_main.py at main · gilfernandes/onepoint_chat
Onepoint Langchain Based Mini Chat App. Contribute to gilfernandes/onepoint_chat development by creating an account on…
The application starts off with a main method. It executes three steps:
- loads all texts from a specific folder and specific pages
- creates the vector database
- initializes the user interface
def main(doc_location: str ='onepoint_chat'):
"""
Main entry point for the application.
It loads all texts from a specific folder and specific web pages,
creates the vector database and initializes the user interface.
:param doc_location: The location of the CSV files
"""
logger.info(f"Using doc location {doc_location}.")
texts, doc_path = load_texts(doc_location=doc_location)
website_texts = load_website_texts([
'https://www.onepointltd.com/',
'https://www.onepointltd.com/do-data-better/'
])
texts.extend(website_texts)
docsearch = extract_embeddings(texts=texts, doc_path=Path(doc_path))
init_streamlit(docsearch=docsearch, texts=texts)The method load_texts loads the texts of the CSV file and concatenates all texts in a single list of document objects.
def load_texts(doc_location: str) -> Tuple[List[str], Path]:
"""
Loads the texts of the CSV file and concatenates all texts in a single list.
:param doc_location: The document location.
:return: a tuple with a list of strings and a path.
"""
doc_path = Path(doc_location)
texts = []
for p in doc_path.glob("*.csv"):
texts.extend(load_csv(p))
logger.info(f"Length of texts: {len(texts)}")
return texts, doc_pathThe method load_csv use LangChain’s CSV loader to load the CSV content as a list of documents.
def load_csv(file_path: Path) -> List[Document]:
"""
Use the csv loader to load the CSV content as a list of documents.
:param file_path: A CSV file path
:return: the document list after extracting and splitting all CSV records.
"""
loader = CSVLoader(file_path=str(file_path), encoding="utf-8")
doc_list: List[Document] = loader.load()
doc_list = [d for d in doc_list if d.page_content != 'Question: \nAnswer: ']
logger.info(f"First item: {doc_list[0].page_content}")
logger.info(f"Length of CSV list: {len(doc_list)}")
return split_docs(doc_list)There is also a load_website_texts method to load text from web pages:
def load_website_texts(url_list: List[str]) -> List[Document]:
"""
Used to load website texts.
:param url_list: The list with URLs
:return: a list of documents
"""
documents: List[Document] = []
for url in url_list:
text = text_from_html(requests.get(url).text)
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100, separator=".")
texts = text_splitter.split_text(text)
for t in texts:
documents.append(Document(page_content=t))
return documentsWe have all texts from CSV and HTML websites and we now extract embeddings with the method below:
def extract_embeddings(texts: List[Document], doc_path: Path) -> Chroma:
"""
Either saves the Chroma embeddings locally or reads them from disk, in case they exist.
:return a Chroma wrapper around the embeddings.
"""
embedding_dir = f"{cfg.chroma_persist_directory}/{doc_path.stem}"
if Path(embedding_dir).exists():
shutil.rmtree(embedding_dir, ignore_errors=True)
try:
docsearch = Chroma.from_documents(texts, cfg.embeddings, persist_directory=embedding_dir)
docsearch.persist()
except Exception as e:
logger.error(f"Failed to process {doc_path}: {str(e)}")
return None
return docsearchFinally, we initialize the Streamlit environment in the init_streamlitfunction. This code expects some form of user question after which it processes the question. It can also process a question from a drop-down with pre-defined questions.
def init_streamlit(docsearch: Chroma, texts):
"""
Creates the Streamlit user interface.
This code expects some form of user question and as soon as it is there it processes
the question.
It can also process a question from a drop down with pre-defined questions.
Use streamlit like this:
streamlit run ./chat_main.py
"""
title = "Ask questions about Onepoint"
st.set_page_config(page_title=title)
st.header(title)
st.write(f"Context with {len(texts)} entries")
simple_chat_tab, historical_tab = st.tabs(["Simple Chat", "Historical Questions"])
with simple_chat_tab:
user_question = st.text_input("Your question")
with st.spinner('Please wait ...'):
process_user_question(docsearch=docsearch, user_question=user_question)
with historical_tab:
user_question_2 = st.selectbox("Ask a previous question", read_history())
with st.spinner('Please wait ...'):
logger.info(f"question: {user_question_2}")
process_user_question(docsearch=docsearch, user_question=user_question_2)Finally, we have the process_user_question function which performs a search in the vector database, creates a question context, which is packed together with the question and sent to the LLM.
def process_user_question(docsearch: Chroma, user_question: str):
"""
Receives a user question and searches for similar text documents in the vector database.
Using the similar texts and the user question retrieves the response from the LLM.
:param docsearch: The reference to the vector database object
:param user_question: The question the user has typed.
"""
if user_question:
similar_docs: List[Document] = docsearch.similarity_search(user_question, k = 5)
response, similar_texts = process_question(similar_docs, user_question)
st.markdown(response)
if len(similar_texts) > 0:
write_history(user_question)
st.text("Similar entries (Vector database results)")
st.write(similar_texts)
else:
st.warning("This answer is unrelated to our context.")There are more functions in the source code, however, they are just simple helper functions.
Conclusion
The chat app we built is really very basic in terms of UI. A better UI can be written perhaps with a UI Javascript framework, like Next.Js or Nuxt. Ideally, you would de-couple the server and client-side by building a REST interface around the chat functionality.
Creating intelligent chat apps based on any knowledge domain is now easy if you have a vector database, an LLM and a UI library like Streamlit. This is a very powerful combination of tools that can really unleash your creativity as a developer.