In this story we are going to dive in LangChain’s LLM Chain class. According to LangChain’s documentation LLM Chain allows to define a prompt template and then send a list of key value pairs to the prompt template for the large language model to process.
How LLM Chain Works
You would typically use LLM Chain using a workflow like this one:
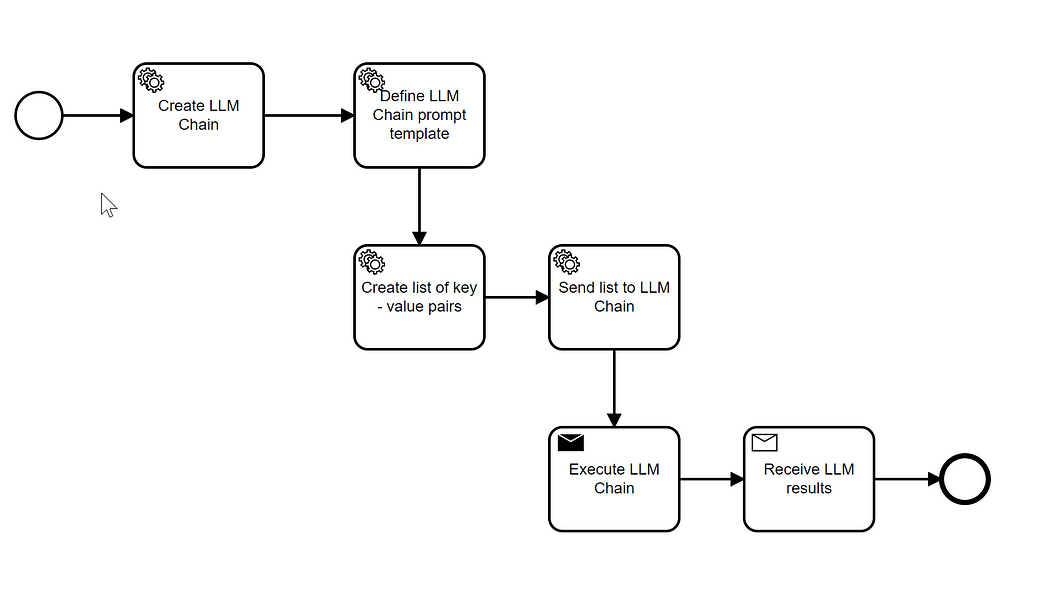
These are the steps:
- Create an LLM Chain object with a specific model. This model can be either a chat (e.g. ‘gpt-3.5-turbo’) or a simple LLM (‘text-davinci-003’)
- Define a prompt template, like e.g: “Please extract the most relevant keywords from {content} the title: {title}. Use a the prefix ‘Keywords:’ before the list of keywords.”
- Create a list of key value pairs using the keys specified in the prompt template, like e.g:
key_value_list = [
{'content': "Across the UK, fossil fuel companies’ broken promises have left scarred and polluted landscapes, and no one held accountable",
'title': "As the toxic legacy of opencast mining in Wales"},
{'content': "The solution is not more fields but better, more compact, cruelty-free and pollution-free factories",
'title': "‘Farming good, factory bad’, we think"},
]- The list of key value pairs is applied to the LLM Chain object which internally sends the requests to the LLM and retrieves the results.
Using LLM Chain with TheGuardian RSS Feeds
In order to better understand how you can use LLM Chain’s we created a simple script which applies multiple prompt templates to TheGuardian’s (a british newspaper) RSS Feeds. RSS feeds contains lists of text based records which can be converted into a key value list.
The purpose of this script is to get the sentiment, keywords of a set of articles and to categorize the articles on the basis of a pre-defined set of categories.
The script then counts the sentiments, categories and keywords found on the columnist’s RSS feed:
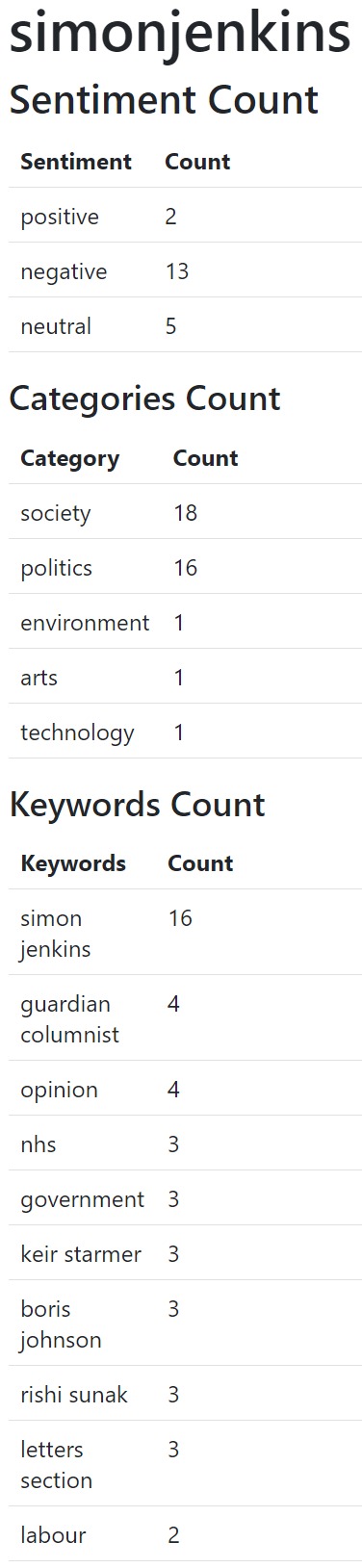
The model we used was ‘gpt-3.5-turbo’
The script can be viewed on Github:
https://github.com/gilfernandes/llm_chain_out/blob/main/langchain_llm_chain_extract.py
Script Operations
The command line script performs the following operations:
- Loops through a list of URLs with the RSS feeds for Guardian columnists, like e.g: http://www.theguardian.com/profile/georgemonbiot/rss or http://www.theguardian.com/profile/simonjenkins/rss
for url in sys.argv[1:]:
process_url(url)
def process_url(url):
"""
Extracts the content of each RSS Feed.
Sends the content of each RSS feed to the LLMChain to apply the prompts to the extracted records.
Creates a data set for each RSS feed which combines the output of the LLM and generates an HTML and Excel file out of it.
:param url: the URL of the RSS feed, like e.g: http://www.theguardian.com/profile/georgemonbiot/rss
"""
print(f"Processing {url}")
zipped_results = []
llm_responses = []
input_list = extract_rss(url)
for prompt_template in prompt_templates:
llm_responses.append(process_llm(input_list, prompt_template))
sentiment_counter = Counter()
categories_counter = Counter()
for zipped in zip(input_list, *llm_responses):
sentiment = {'sentiment': zipped[1]['text']}
categorized_sentiment = categorize_sentiment(zipped[1]['text'])
sentiment_counter[categorized_sentiment] += 1
sentiment_category = {'sentiment_category': categorized_sentiment}
keywords = {'keywords': zipped[2]['text']}
raw_categories = zipped[3]['text']
classification = {'classification': raw_categories}
sanitized_topics = sanitize_categories(raw_categories)
categories_counter.update(sanitized_topics)
sanitized_categories = {'topics': ",".join(sanitized_topics)}
full_record = {
**zipped[0],
**sentiment,
**keywords,
**sentiment_category,
**classification,
**sanitized_categories
}
zipped_results.append(full_record)
result_df = pd.DataFrame(zipped_results)
title = url.replace(":", "_").replace("/", "_")
serialize_results(url, result_df, title, sentiment_counter, categories_counter)- It extracts for each URL multiple articles (typically 20). For each article only the content and the title are extracted.
def extract_rss(url):
"""
Extracts the content and title from a URL.
:param url The RSS feed URL, like e.g: http://www.theguardian.com/profile/georgemonbiot/rs
"""
response = requests.get(url)
tree = ElementTree.fromstring(response.content)
content = []
for child in tree:
if child.tag == 'channel':
for channel_child in child:
if channel_child.tag == 'item':
content.append({'content': channel_child[2].text, 'title': channel_child[0].text})
return content- For each article the script then loops through a collection of prompts:
- “Please tell me the sentiment of {content} with this the title: {title}? Is it very positive, positive, very negative, negative or neutral? Please answer using these expressions: ‘very positive’, ‘positive’, ‘very negative’, ‘negative’ or ‘neutral’”
- “Please extract the most relevant keywords from {content} the title: {title}. Use a the prefix ‘Keywords:’ before the list of keywords.”
- “Please categorize the following content using the following content {content} with title {title} using these categories: ‘politics’, ‘environment’, ‘society’, ‘sports’, ‘lifestyle’, ‘technology’, ‘arts’“
prompt_templates = [(
"Please tell me the sentiment of {content} with this the title: {title}? Is it very positive, positive, very negative, negative or neutral? "
+ "Please answer using these expressions: 'very positive', 'positive', 'very negative', 'negative' or 'neutral'"),
"Please extract the most relevant keywords from {content} the title: {title}. Use a the prefix 'Keywords:' before the list of keywords.",
"Please categorize the following content using the following content {content} with title {title} using these categories: " + ",".join(accepted_categories)
]
model = 'gpt-3.5-turbo'
def process_llm(input_list: list, prompt_template):
"""
Creates the LLMChain object using a specific model
:param input_list a list of dictionaries with the content and title of each article
:param prompt_template A single prompt template with content and title parameters
"""
llm = ChatOpenAI(temperature=0, model=model)
# You can also use another model. text-davinci-003 is more expensive than gpt-3.5-turbo
# llm = OpenAI(temperature=0, model='text-davinci-003')
llm_chain = LLMChain(
llm=llm,
prompt=PromptTemplate.from_template(prompt_template)
)
return llm_chain.apply(input_list)- After this loop we have a response about the sentiment, another one with the keywords and one with the categories of each article. We sanitize the LLM output to be able to count sentiments, categories and keywords.
def sanitize_categories(text):
text = text.lower()
sanitized = []
for cat in accepted_categories:
if cat in text:
sanitized.append(cat)
return sanitized
def sanitize_keywords(text):
text = text.lower()
text = text.replace("keywords:", "").strip()
sanitized = [re.sub(r"\.$", "", s.strip()) for s in text.split(",")]
return sanitized
def categorize_sentiment(text):
text = text.lower()
if 'very negative' in text:
return 'very negative'
elif 'negative' in text:
return 'negative'
elif 'very positive' in text:
return 'very positive'
elif 'positive' in text:
return 'positive'
return 'neutral'- We use some counters to count the sentiments and categories of each author (See process_url code above)
- Finally the script generates an Excel file and an HTML file with the sentiment count, category count and all the prompt responses for each article
def serialize_results(url, result_df, title, sentiment_counter, categories_counter):
"""
Converts the results to an Excel sheet or HTML page. The HTML page also contains the counter information.
:param url The RSS feed URL
:param result_df The combined raw data and with the LLM output
:param title The RSS feed URL with some modified characters
:param sentiment_counter The counter with the sentiment information
:param categories_counter The counter with the counted categories
"""
result_df.to_excel(target_folder/f"{title}.xlsx")
html_file = target_folder/f"{title}.html"
html_content = result_df.to_html(escape=False)
# Make sure the file is written in UTF-8
with open(html_file, "w", encoding="utf-8") as file:
file.write(html_content)
sentiment_html = generate_sentiment_table(sentiment_counter, "Sentiment")
categories_html = generate_sentiment_table(categories_counter, "Category")
with open(html_file, encoding="utf8") as f:
content = f"""<html>
<head>
<meta charset="UTF-8" />
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-9ndCyUaIbzAi2FUVXJi0CjmCapSmO7SnpJef0486qhLnuZ2cdeRhO02iuK6FUUVM" crossorigin="anonymous">
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/js/bootstrap.bundle.min.js" integrity="sha384-geWF76RCwLtnZ8qwWowPQNguL3RmwHVBC9FhGdlKrxdiJJigb/j/68SIy3Te4Bkz" crossorigin="anonymous"></script>
</head>
<body>
<div class="container-fluid">
<h1>{re.sub(r'.+?theguardian.com/profile', '', url)}</h1>
<h3>Sentiment Count</h3>
{sentiment_html}
<h4>Categories Count</h4>
{categories_html}
{f.read()}
</div>
</body>
</html>"""
content = content.replace('class="dataframe"', 'class="table table-striped table-hover dataframe"')
with open(html_file, "w", encoding="utf8") as f:
f.write(content)Sample Script Output
This is the script output for example for the following columnists:
Conclusion
LangChain’s LLM Chain provides a very convenient way to interact with an LLM when you have a list based input to which you want to apply a pre-defined LLM prompt with parameters.