In this story, we will explore LangChain’s capabilities for question-answering based on a set of documents. We will describe a simple example of an HR application which scans a set of files with CVs in a folder and asks ChatGPT 3.5 questions about the candidates.
We have used LangChain v0.0.190 here.
The questions/instructions asked here are:
What is the name of the job candidate?
What are the specialities of this candidate?
Please extract all hyperlinks.
How many years of experience does this candidate have as a mobile developer?
Which universities are mentioned in the CV?
This simple HR application is embedded in a Web Server (using FastAPI with uvicorn) which displays the answers to these questions as a simple webpage.
LangChain Document Processing Capabilities
LangChain has multiple document processing chains:
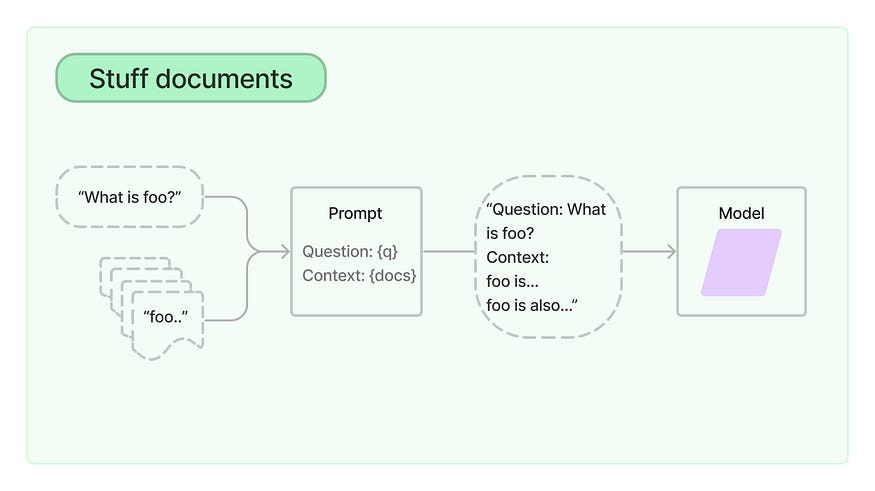
The Stuff chain includes a document into its question (prompt) context and exposes the question (prompt) to the LLM.
This is the image which depicts the Stuff document chain from the Langchain documentation:
Application Flow
There are two workflows in our HR application:
- the first workflow (QA Creation Process) creates the question and answer list for each specific candidate
- the second one is about getting a web request, converting it to HTML and sending a response back
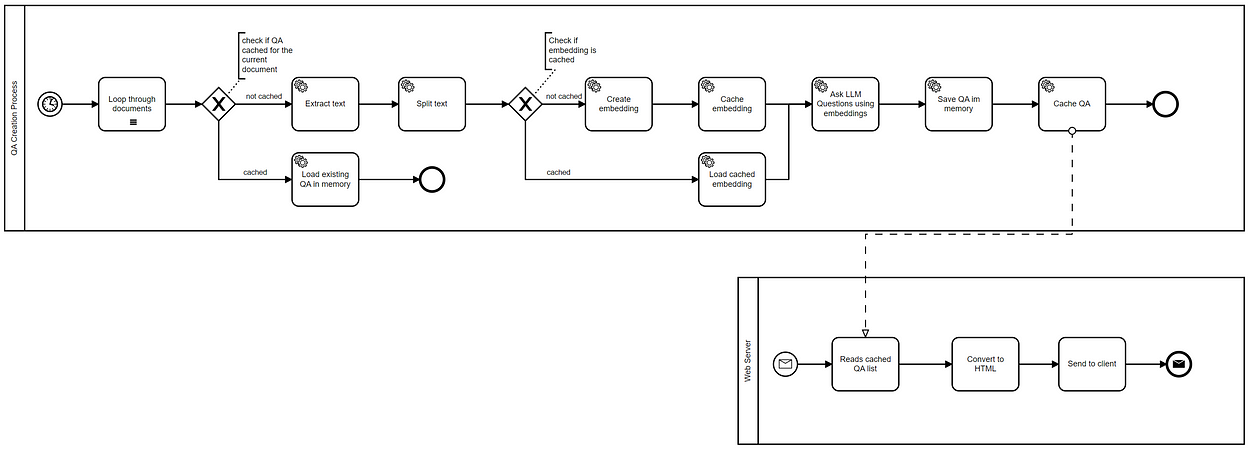
The QA Creation Process executes the following steps:
- It loops all documents in a pre-defined folder (only pdf and docx files)
- It checks whether the question-answers for a specific candidate have been previously cached or not.
- If the question-answers were previously cached, then they get loaded into memory
- In case the QA’s were not cached, the text gets extracted and split.
- The workflow checks whether there are any cached embeddings.
- If there are cached embeddings then they are loaded into memory.
- If not ChatGPT is queried and a set of embeddings for the extracted text is retrieved
- The embeddings set are saved in a local directory and, thus cached.
- ChatGPT is queried for all answers using the embeddings set.
- The QA’s are stored in memory and cached on the file system.
To know what embeddings are, please visit OpenAI’s page about embeddings.
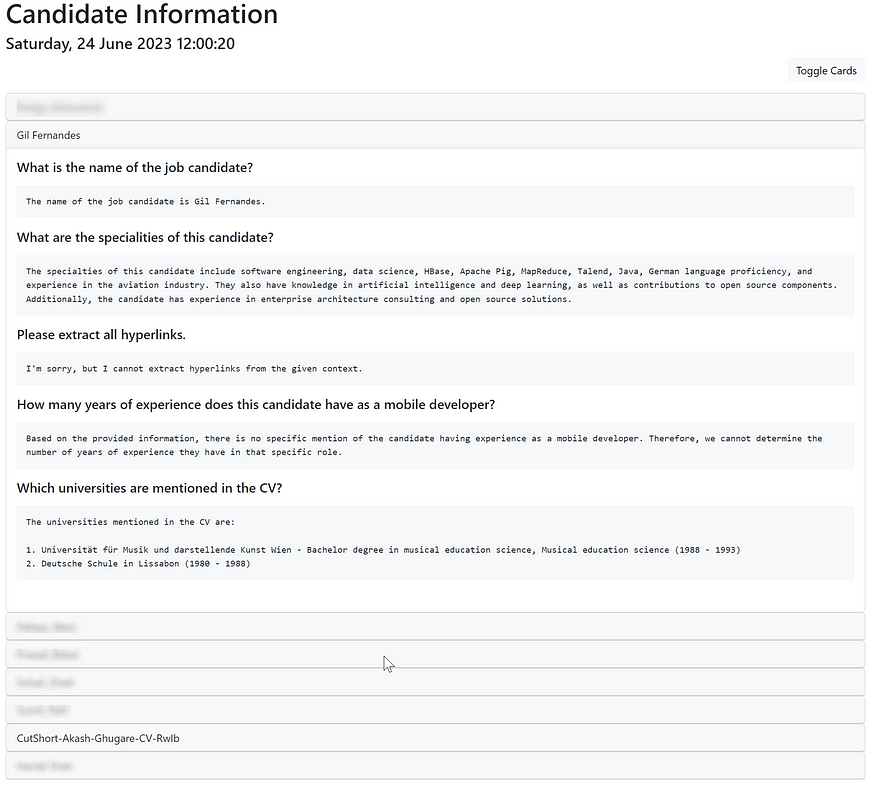
User Interface
The user interface of this application is a single page that displays expandable cards with the QA’s related to a user:
Setup and Execution
The implementation of the flow described above can be found in this GitHub repository:
GitHub - gilfernandes/document_stuff_playground: Playground project used to explore Langchain's…
Playground project used to explore Langchain's Document Stuffing with question answering - GitHub …
Implementation
We mentioned that the web application has two flows. The implementation has two parts: the question/answer creation process and the web server:
Question / answer creation process
document_stuff_playground/document_extract.py at main · gilfernandes/document_stuff_playground
Playground project used to explore Langchain's Document Stuffing with question answering …
We have used the “gpt-3.5-turbo-16k” model together with OpenAI embeddings.
class Config():
model = 'gpt-3.5-turbo-16k'
llm = ChatOpenAI(model=model, temperature=0)
embeddings = OpenAIEmbeddings()
chunk_size = 2000
chroma_persist_directory = 'chroma_store'
candidate_infos_cache = Path('candidate_infos_cache')
if not candidate_infos_cache.exists():
candidate_infos_cache.mkdir()We define a data class to contain the name of the file and the question/answer pairs:
@dataclass
class CandidateInfo():
candidate_file: str
questions: list[(str, str)]The function does the bulk of the work and loops through the files, extracts their content, creates the embeddings, creates the answers and collects the results is this one here:
def extract_candidate_infos(doc_folder: Path) -> List[CandidateInfo]:
"""
Extracts the questions and answers from each pdf or docx file in `doc_folder`
and saves these in a list. First it loops through the files, extracts their content
as embeddings and caches these and then interacts with ChatGPT. The answers are then
saved in a data structure and cached. If the answers are already available for a candidate
they are read from a pickled file.
:param doc_folder The folder with the candidate documents.
:return the list with candidate question' and answers.
"""
if not doc_folder.exists():
print(f"Candidate folder {doc_folder} does not exist!")
return []
candidate_list: list[CandidateInfo] = []
extensions: list[str] = ['**/*.pdf', '**/*.docx']
for extension in extensions:
for doc in doc_folder.rglob(extension):
file_key = doc.stem
cached_candidate_info = read_saved_candidate_infos(file_key)
if cached_candidate_info is None:
docsearch = process_document(doc)
print(f"Processed {doc}")
if docsearch is not None:
qa = RetrievalQA.from_chain_type(llm=cfg.llm, chain_type="stuff", retriever=docsearch.as_retriever())
question_list = []
for question in questions:
# Ask the question here
question_list.append((question, qa.run(question)))
candidate_info = CandidateInfo(candidate_file=file_key, questions=question_list)
write_candidate_infos(file_key, candidate_info)
candidate_list.append(candidate_info)
else:
print(f"Could not retrieve content from {doc}")
else:
candidate_list.append(cached_candidate_info)
return candidate_listWe also cache the results to prevent too many API calls.
We have a function which pickles (serializes) the collected results:
def write_candidate_infos(file_key, candidate_info):
cached_file = cfg.candidate_infos_cache/file_key
with open(cached_file, "wb") as f:
pickle.dump(candidate_info, f)And another one which checks if the CV file already has corresponding QA’s on the local file system:
def read_saved_candidate_infos(file_key: str) -> Union[None, CandidateInfo]:
cached_file = cfg.candidate_infos_cache/file_key
try:
if cached_file.exists():
with open(cached_file, "rb") as f:
return pickle.load(f)
except Exception as e:
print(f"Could not process {file_key}")
return NoneThe function below extracts and persists embeddings on the local file system:
def extract_embeddings(texts: List[Document], doc_path: Path) -> Chroma:
"""
Either saves the Chroma embeddings locally or reads them from disk, in case they exist.
:return a Chroma wrapper around the embeddings.
"""
embedding_dir = f"{cfg.chroma_persist_directory}/{doc_path.stem}"
if Path(embedding_dir).exists():
return Chroma(persist_directory=embedding_dir, embedding_function=cfg.embeddings)
try:
docsearch = Chroma.from_documents(texts, cfg.embeddings, persist_directory=embedding_dir)
docsearch.persist()
except Exception as e:
print(f"Failed to process {doc_path}: {str(e)}")
return None
return docsearchWe are using Chroma, an open-source embedding database here. Chroma allows to save embeddings (numerical vectors representing tokens) and their metadata.
This function reads the document and extracts the text:
def process_document(doc_path) -> Chroma:
"""
Processes the document by loading the text from the document.
There are two supported formats: pdf and docx. Then it splits
the text in large chunks from which then embeddings are extracted.
:param doc_path a path with documents or a string representing that path.
:return a Chroma wrapper around the embeddings.
"""
if not isinstance(doc_path, Path):
doc_path = Path(doc_path)
if not doc_path.exists():
print(f"The document ({doc_path}) does not exist. Please check")
else:
print(f"Processing {doc_path}")
loader = (PDFPlumberLoader(str(doc_path)) if doc_path.suffix == ".pdf"
else Docx2txtLoader(str(doc_path)))
doc_list: List[Document] = loader.load()
print(f"Extracted documents: {len(doc_list)}")
for i, doc in enumerate(doc_list):
i += 1
if len(doc.page_content) == 0:
print(f"Document has empty page: {i}")
else:
print(f"Page {i} length: {len(doc.page_content)}")
text_splitter = CharacterTextSplitter(chunk_size=cfg.chunk_size, chunk_overlap=0)
texts = text_splitter.split_documents(doc_list)
return extract_embeddings(texts, doc_path)Web Server
This part of the implementation serves the results which are stored in memory using the FastAPI framework. You could also just create a REST service and develop an application with a modern web framework.
Our implementation uses a scheduled background thread to update the list of QAs about the candidates in case CVs are saved in the input directory:
class CandidateCache():
candidate_info_html = "<p>Processing, please wait ...</p>"
candidate_cache = CandidateCache()
SLEEP_TIME = 60 * 10
class BackgroundTasks(threading.Thread):
"""
Processes documents and query Chat GPT in the background.
"""
def __init__(self, candidate_cache: CandidateCache, sleep_time = SLEEP_TIME):
super().__init__()
self.candidate_cache, self.sleep_time = candidate_cache, sleep_time
self.data_cache = sleep_timeThen You can then find an HTML-generating endpoint that renders a simple page:
@app.get("/candidates.html", response_class=HTMLResponse)
async def hello_html():
def generate_timestamp():
# Get the current date and time
now = datetime.now()
# Get the weekday, day, month, year, and time in English
weekday = now.strftime("%A")
day = now.strftime("%d")
month = now.strftime("%B")
year = now.strftime("%Y")
time = now.strftime("%H:%M:%S")
# Create the timestamp string
timestamp = f"{weekday}, {day} {month} {year} {time}"
return timestamp
return f"""
<html>
<head>
<meta charset="UTF-8" />
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-9ndCyUaIbzAi2FUVXJi0CjmCapSmO7SnpJef0486qhLnuZ2cdeRhO02iuK6FUUVM" crossorigin="anonymous">
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/js/bootstrap.bundle.min.js" integrity="sha384-geWF76RCwLtnZ8qwWowPQNguL3RmwHVBC9FhGdlKrxdiJJigb/j/68SIy3Te4Bkz" crossorigin="anonymous"></script>
<style>
pre {{
white-space: pre-wrap;
}}
</style>
</head>
<body>The server is executed via uvicorn:
if __name__ == '__main__':
print("Fast API setup")
uvicorn.run(app, host="0.0.0.0", port=8000)Conclusion
It is relatively easy to build a basic human resources application based on documents with LangChain which uses LLMs to answer questions about these documents. Much of the heavy lifting (communication with LLM, embeddings generation) is done by LangChain, which provides wide support for different file types too.
For human resources, you could also create an application which ranks candidates with the Map re-rank chain. LangChain would also support such functionality, but we will explore that in subsequent blogs.