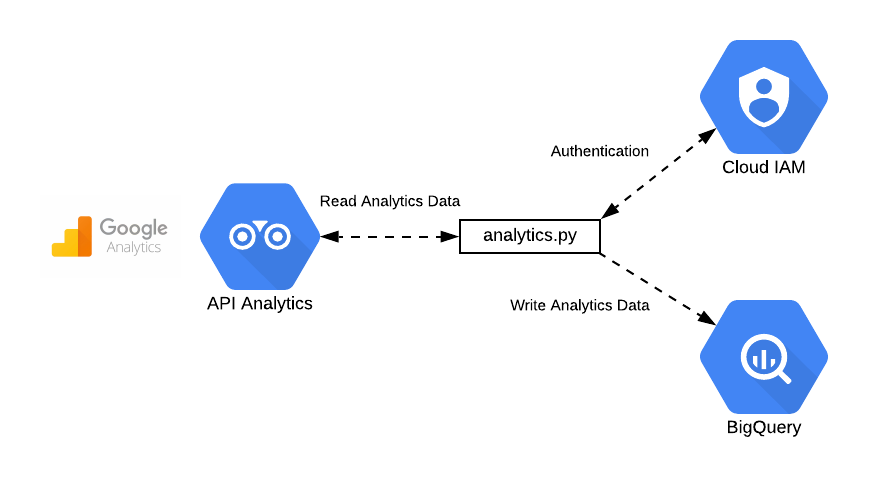
If businesses do not have their data ready for AI, there is a high chance that your organisation will be in a classic “garbage in, garbage out” scenario.
“If 80 percent of our work is data preparation, then ensuring data quality is the most critical task for a machine learning team.
¬Andrew Ng, Professor of AI at Stanford University
Preparing data for AI implementation requires meticulous attention to quality and structure. Research indicates that companies investing in data preparation see significant improvements in AI model accuracy and reliability, gaining a competitive advantage.
MatchX’s AI-powered platform streamlines this critical process, helping organisations transform raw data into valuable insights through automated quality checks and intelligent matching algorithms.
Step 1: Define Clear AI Objectives and Understand Data Requirements
Successful AI implementation begins with clarity of purpose.
Before diving into data collection or preparation, organisations must establish precisely what business problems they’re solving with AI. This critical first step prevents resource waste. This was a hard lesson learnt by 36% of UK organisations whose AI projects failed due to inadequately defined business problems.
- Start by aligning your AI goals with concrete business objectives. Ask what specific decisions or processes you aim to improve and how success will be measured.
This alignment focuses your data preparation efforts exclusively on relevant information. For instance, if reducing customer churn by 10% is your goal, you’ll need customer behaviour data, product usage metrics, and feedback, not just any available data.
Once objectives are clear, identify the specific data types required for your AI solution. Different use cases demand different inputs. Assess your current data assets against these requirements, evaluating completeness, consistency, accuracy, and freshness.
Step 2: Data Collection and Integration
After defining clear objectives, the next critical phase involves gathering and consolidating your data assets.
Valuable information often exists in isolated silos across various systems and formats. The collection process should encompass both internal repositories (transaction records, CRM systems) and external sources (market research, open datasets) to ensure sufficient diversity. This breadth is essential as AI systems trained on limited data segments often develop blind spots and biases that compromise their effectiveness.
- With approximately 80% of enterprise data existing in unstructured formats: documents, images, and audio files, organisations must extend collection efforts beyond traditional databases.
Specialised processing techniques like NLP pipelines and OCR technology can transform this raw information into structured formats suitable for analysis. Advanced platforms like MatchX facilitate this process through AI-powered document ingestion capabilities that maintain data relationships while ensuring a unified representation.
Step 3: Data Cleaning and Preprocessing
Raw data typically contains numerous imperfections requiring systematic resolution. With your data collected and integrated, the critical task of cleaning and preprocessing begins, a phase that often consumes up to 80% of data scientists’ time.
Missing values must be addressed through strategic imputation rather than simple deletion, which can introduce bias. Inconsistencies in formats and representations need standardization:
- Ensuring uniform date formats
- Consistent categorical values
- Aligned measurement units
Error detection requires both automated anomaly identification and domain expertise to correct impossible values, duplicates, and outliers that could mislead your AI models.
AI-driven automation transforms this through platforms like MatchX. Its self-learning models can detect inconsistent patterns and suggest corrections, while the platform’s Quality Centre validates data at scale. These tools accelerate cleaning and also enhance reproducibility by encoding preparation workflows that can be consistently applied to new data streams.
Step 4: Data Transformation and Feature Engineering
With clean data established, the next critical phase involves reshaping information into formats optimised for AI consumption and extracting meaningful patterns through feature engineering.
Most machine learning algorithms require numerical inputs in specific formats, necessitating several key transformations.
- Numeric data must be normalised to standard ranges to prevent features with larger scales from dominating the model.
- Categorical variables require encoding into numeric representations using techniques like one-hot encoding or label encoding.
- Additional transformations might include creating interaction terms that capture relationships between features or applying dimensionality reduction to datasets with excessive features.
Feature engineering extends beyond basic transformations by leveraging domain expertise to extract signals from raw data. Rather than feeding transaction logs directly into a model, for instance, derived features like “average spending last quarter” often provide more predictive power.
This process requires particular attention when handling complex data types—extracting sentiment scores from text, using pre-trained networks to generate feature vectors from images, or converting time series into lag features.
The ultimate goal is to bridge the gap between raw information and optimised learning inputs, ensuring your model receives the most relevant signals for accurate predictions.
Step 5: Ensuring Data Quality, Governance, and Compliance
As your AI initiatives progress from prototype to production, both the data landscape and regulatory environment will evolve, requiring robust frameworks to maintain data integrity throughout their lifecycle.
A comprehensive data governance strategy provides the essential foundation for sustainable AI operations. This framework establishes clear ownership of datasets, defines responsibility for quality, and documents how changes are controlled and approved.
Key components of a data governance program for AI data include:
- Data quality management
- Metadata and cataloguing
- Data lineage and versioning
- Roles and responsibilities
- Training and culture
Effective governance includes implementing regular quality checks with specific metrics, such as maintaining customer data that is 99% duplicate-free or keeping missing values below 1% for critical fields.
In regions like the UK, Europe, and North America, data privacy and protection laws are a critical factor in AI data preparation. Non-compliance can result in heavy fines and reputational damage. Thus, ensuring compliance is a non-negotiable part of the data prep process. Several compliance considerations for AI data:
- Legal basis and consent
- Minimisation and relevance
- Anonymisation or pseudonymization
- Access controls and security
- Regulatory requirements
- Ethical considerations
To combat a horde of compliance, organisations are opting for synthetic data generation methods. It creates statistically similar datasets without using actual personal information, enabling privacy-compliant model training by design.
Monitoring Data Quality Continuously
The final critical component is continuous quality monitoring.
Data is not static – its characteristics evolve as business conditions change and new sources are integrated. Implement automated systems to track key quality indicators and alert teams when metrics exceed acceptable thresholds.
By treating data preparation as a continuous lifecycle rather than a one-time project, organisations create the sustainable foundation necessary for long-term AI success.
Conclusion
Effective data preparation forms the critical foundation upon which successful AI initiatives are built. By methodically following the outlined steps: defining clear business objectives, collecting diverse data sources, implementing thorough cleaning processes, transforming raw data through feature engineering, and establishing governance frameworks, organisations dramatically improve their AI project outcomes.
Studies consistently identify poor data quality as a primary barrier to AI adoption, making meticulous preparation a strategic imperative rather than a technical afterthought.
Tools like MatchX streamline this journey by integrating AI-powered data quality mechanisms that validate, cleanse, and maintain information integrity throughout the entire lifecycle, enabling organisations to transform their data assets into genuine competitive advantages.
Contact us or Visit us for a closer look at how VE3’s solutions can drive your organization’s success. Let’s shape the future together.
1. Why is data preparation considered the most critical aspect of AI implementation?
Data preparation is fundamental because AI models can only be as good as the data they’re trained on. With data scientists spending up to 80% of their time on preparation activities, this phase directly determines model accuracy and reliability. Poor preparation leads to flawed outputs, while high-quality data enables AI systems to deliver accurate insights that drive business value.
2. How can organisations effectively handle unstructured data for AI applications?
Organisations should employ specialised processing techniques for unstructured content, which comprises approximately 80% of enterprise data. For text, implement NLP pipelines to extract meaningful features. For images or documents, utilise OCR technology and computer vision tools. The key is maintaining contextual information while transforming unstructured content into structured formats that AI algorithms can process.
3. What role does feature engineering play in AI data preparation?
Feature engineering bridges raw data and AI algorithms by transforming information into more predictive inputs. Rather than feeding transaction logs directly into models, create derived features like “average spending patterns” that capture meaningful patterns. This process requires both domain expertise and technical skill, often making the difference between mediocre and exceptional model performance, particularly with tabular data.
4. How should companies approach data governance for AI initiatives?
Establish a comprehensive governance framework that defines data ownership, quality responsibilities, and change management procedures. Implement regular quality checks with specific metrics (e.g., maintaining customer data that is 99% duplicate-free). Create data catalogues documenting available assets and their sources, and track lineage to understand information flow. Assign dedicated data stewards to champion quality across the organisation.
5. What compliance considerations are most important when preparing data for AI?
Organizations must verify they have a legal basis for AI data usage under regulations like GDPR and CCPA. Apply data minimization principles by using only necessary information, implement anonymization techniques for sensitive data, and establish strict access controls. Consider synthetic data generation to create statistically similar datasets without using actual personal information. Document processes thoroughly to demonstrate compliance with evolving regulatory requirements.