Real-world information retrieval is rarely uniform. Some queries demand exact token alignment; others depend on conceptual similarity, and many contain both signals at once. Hybrid search is an integration of lexical scoring and semantic retrieval that simply runs two pipelines side by side.
Every query is treated as a multi-signal inference task.
Foundations of Search Paradigms
To build or deploy AI-powered information retrieval systems, it is necessary to understand the differences between search paradigms and how lexical and semantic search merge to create more advanced and accurate search results.
Lexical Search
Lexical search is the classic keyword-matching approach. It doesn’t “understand” what you mean. It only matches the exact tokens you type to the exact tokens stored in your documents.
A simple way to define it:
Lexical search works the way you search your email inbox.
If you type “Q2 budget review”, your email client finds messages that literally contain
“Q2”, “budget”, and “review.”
If you used slightly different wording like “Second-quarter financial plan discussion”, you won’t find it because the tokens don’t match.
Lexical search typically relies on traditional databases like SQL systems, NoSQL document stores, or inverted index engines to scan and compare tokenized query terms against tokenized document fields.
Semantic Search
Semantic search removes the constraints of token matching in lexical search and builds relationships between ideas, not strings.
Large banks, insurers, and government agencies still use Documentum, where full-text retrieval is entirely lexical. A COO searching internally for, “customer dissatisfaction reasons for premium clients” would only see documents containing exact tokens using Documentum.
With a semantic search system, conceptually related material such as documents on NPS decline, renewal risk, or churn drivers in top-tier accounts would be retrieved, even if the query words do not appear in the files.
Why Hybrid Search
By this point, you already understand what hybrid search is, but the value comes from how it combines the strengths of lexical and semantic retrieval to get results that neither could deliver alone.
Lexical retrieval ensures critical documents are captured while semantic retrieval uncovers related information that may not contain the exact keywords.
These signals are combined through fusion, then ranked and filtered using relevance modeling that considers intent, document quality, authority, and recency.
The result is a system that feels intuitive.
Hybrid Retrieval Pipeline
Hybrid retrieval is only possible because it has several paths that extract different types of signals from one query.
Each path represents a different slice of the input query, lexical extracts literal intent, semantic extracts conceptual intent, and the fusion path or layer reconciles both to form a unified view of context.
Let’s look at what signals these paths capture and how all paths work together.
Lexical Retrieval Path
The lexical path focuses on the actual words a user types — IDs, codes, product names, error messages, exact terms.
It usually runs on BM25, which is just a smart scoring formula that checks:
- how often the keyword appears in a document
- how unique or important that keyword is
- and how long the document is
This path is essential when precision matters:
“INV-98217,” “error 504,” “Form 16,” “Q4 revenue.xlsx”
What it captures: literal phrasing, keywords, numbers, filenames, and exact text.
Semantic Retrieval Path
This path tries to understand the meaning behind the words, not the exact phrasing.
It uses vector embeddings, which you can think of as giving each sentence or document a numeric meaning-fingerprint. Because these fingerprints capture context, the system can match sentences like:
“System downtime analysis” = “why did the platform go offline?”
Even though the words are different, the meaning overlaps.
This path shines in natural, vague, or conceptual queries:
“How do I reduce customer churn?”, “guidelines for vendor risk?”, “show me documents about onboarding issues.”
What it captures: intent, concepts, paraphrases, synonyms, and topic similarity.
Fusion Layer
Once lexical and semantic results are ready, the search uses fusion to combine them.
Fusion can simply blend scores (weighted fusion) or blend ranks (RRF — a simple method that rewards documents appearing in both lists).
Fusion makes sure:
- exact matches don’t get lost
- meaning matches are still surfaced
- and both views reinforce each other
What it captures: a balanced view of literal intent + conceptual meaning.
Ranking Strategies
After fusion, hybrid search must decide which results appear first. Ranking is the step that turns combined signals into an ordered list that feels actionable. Different strategies can be applied depending on context, query type, and importance of “exact versus conceptual” matches.
Independent Ranking
This is the simplest approach. Each retrieval path- lexical and semantic, is scored separately. The results from each path are ranked within their own list without cross-comparison.
Example:
- Lexical path finds “Invoice INV-98217” and ranks it highest because it is an exact match.
- Semantic path finds “outstanding client payment issues” and ranks it based on relevance to the concept of payments.
The system presents both ranked lists to the user, either side by side or as a merged view.
What it captures: preserves each path’s unique perspective, useful when exact matches and conceptual relevance need to be visible independently.
Pot-Fusion Ranking
Pot-Fusion ranking combines the results of lexical and semantic lists before final ranking. It uses simple rules like:
- Give bonus points to documents appearing in both lists
- Merge the remaining results based on weighted scores
Example:
- Document A appears in both lexical and semantic results → gets higher priority
- Document B appears only in semantic results → weighted slightly lower
This ensures that documents that satisfy both literal and conceptual relevance rise to the top.
What it captures: balance between exact matches and semantic relevance, highlighting documents that satisfy multiple signals simultaneously.
Advanced Re-Ranking
The most sophisticated method. Here, an additional AI model (like a cross-encoder or transformer) examines the full query and document content after fusion. It fine-tunes the order based on:
- Contextual alignment of query and document
- Document authority and recency
- User or organizational priorities
Example:
- Query: “High-value client churn drivers”
- Candidate documents: 10 matched via fusion
- Re-ranking ensures a recent “Enterprise account churn report” appears first, while older generic churn guidelines are pushed down
What it captures: ultimate precision and relevance, factoring in all available signals and external metadata.
Relevance Modeling
It evaluates each document against multiple signals like alignment with user intent, authority of the source, topical accuracy, recency, and historical user interactions.
For enterprises, this means search results for surface actionable insights fast, while technology teams get prioritized data without delay. Unlike generic scoring, relevance modeling contextualizes information based on business priorities, ensuring decisions are informed by both strategy and relevance.
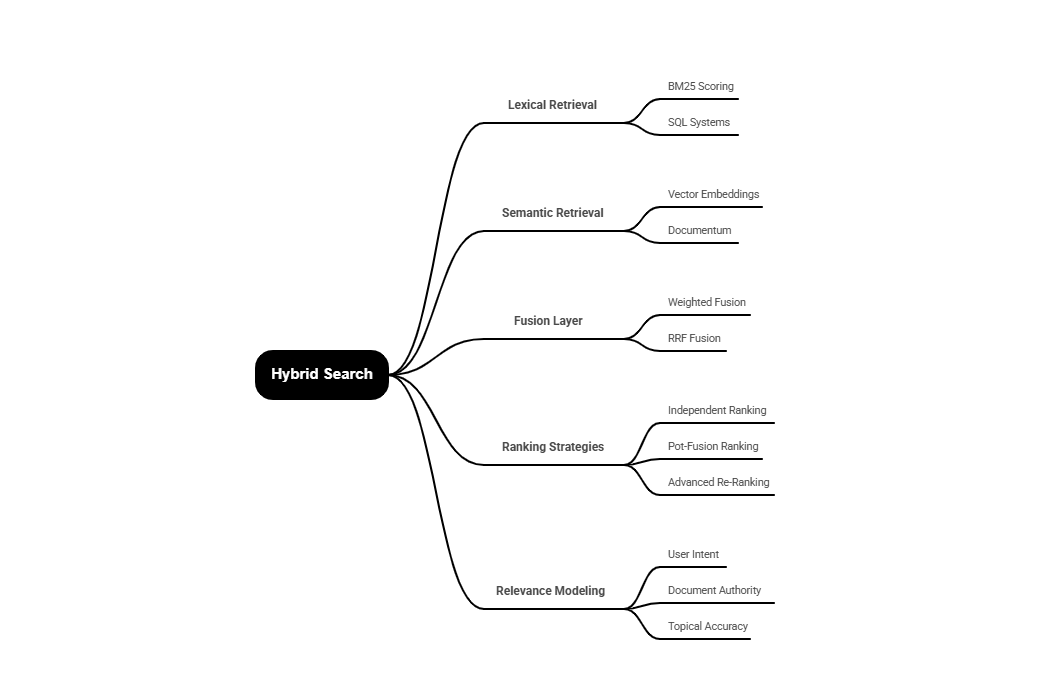
Hybrid Architecture
Hybrid search architecture is a multi-layered system designed to extract and integrate signals efficiently. It can be understood in these steps:
Pipeline Visualization
Step | Function | Captures |
Query Input | User enters search | User intent |
Lexical Retrieval | Exact keyword matching | IDs, filenames, numbers |
Semantic Retrieval | Contextual matching | Concepts, paraphrases |
Fusion | Merge scores/ranks | Combined view |
Ranking | Order results | Priority, alignment, recency |
Relevance Modeling | Refine final list | Actionable, authoritative results |
Use Cases
Strategic Knowledge Retrieval
Hybrid search enables retrieval of exact regulatory clauses, financial tables, or board presentations while also surfacing related trends, risk analyses, and cross-departmental reports.
Unlike traditional search, it ensures that high-level decision-makers see both exact evidence and contextually relevant data in a single view.
Context-Aware Internal Support Systems
IT and HR help desks face queries ranging from exact error codes to vague procedural questions.
Hybrid search can return a precise document such as “VPN outage error 504” alongside semantically relevant guides like “common connectivity issues and resolutions.” This dual-layer retrieval reduces repeated escalations and empowers employees to resolve issues independently.
Cross-Domain Research and Analytics
Analysts working on market research, compliance, or supply chain risk often struggle to connect structured and unstructured data. Hybrid search links exact IDs, contract numbers, or product codes with conceptual insights like vendor risk trends or operational bottlenecks. This creates actionable intelligence that neither pure keyword search nor semantic search could deliver alone.
Domain-Specific RAG Knowledge Bases
In legal, finance, or healthcare contexts, hybrid search goes beyond keyword matching.
It retrieves recent case rulings, policy updates, or clinical guidelines and maps them to conceptual patterns such as regulatory impact or patient risk categories.
Unlike standard search, this approach reduces the risk of missing critical but conceptually linked information.
Multilingual and Multimodal Enterprise Search
Global organizations operate across languages and content formats. Hybrid retrieval capability allows a single query to access reports in English, contracts in Spanish, and email threads or chat logs, while maintaining semantic alignment.
Best Practices
Define and Separate Signals
Identify which information must be captured literally (codes, IDs) and which can be conceptual (trends, patterns). Clear separation ensures hybrid search balances exactness with breadth, making outputs actionable for both tech teams and executives.
Implement Multi-Stage Ranking
Apply independent ranking first, then pot-fusion, and finally advanced re-ranking to prioritize documents that satisfy multiple signals simultaneously. This ensures critical documents rise to the top while maintaining contextual coverage.
Enrich with Metadata
Tag content with department, project, or category labels. Metadata enhances relevance scoring and ensures that both lexical and semantic signals align with organizational priorities.
Chunk Content for Context Preservation
Large reports, emails, and PDFs should be divided into meaningful segments to ensure hybrid search captures the most relevant context for both literal and conceptual queries.
Continuous Evaluation and Feedback
Track precision, recall, and user engagement. Regular evaluation allows fine-tuning of scoring weights, fusion logic, and ranking strategies to maintain relevance as enterprise data and priorities evolve.
Hybrid Search with PromptX
PromptX makes hybrid search seamless by combining vector, keyword, and metadata search within a single platform. With unified access layers and auto-tagging, teams can get precise and relevant results from diverse enterprise sources without complex setup.
For enterprises, this simplifies query construction with semantic, lexical, and hybrid retrieval operators that automatically interpret your data and user intent. On this platform, you get many more features such as Workspaces, Knowledge Stack, Chat Collection, and Document Classification.