This blog will explore of one of LangChain’s agents: the chat agent with ReAct logic. There are a good number of LangChain agents mentioned in the LangChain documentation, however, we are just going to focus on the ReAct Agent.
So what is the ReAct Agent according to the LangChain documentation?
This agent uses the ReAct framework to determine which tool to use based solely on the tool’s description. Any number of tools can be provided. This agent requires that a description is provided for each tool.
Note: This is the most general purpose action agent.
This blog also presents a simple implementation of a chat agent using 3 tools that are packaged in LangChain v.0.0.220. For more details about our playground agent about please see below.
Main Idea
The chat agent with ReAct logic has access to a specific list of tools and to a Large Language Model (LLM). Upon receiving a user-generated message the chat agent asks the LLM which is the best suited tool to answer the question. Optionally it might also send the final answer.
It might choose a tool. If this is the case, the question or keywords of it are executed against the tool. The tool then returns an output which is then used against the LLM to again plan what to do next: either choose another tool or give the final answer.
So the agent uses the LLM for planning what to do next in a loop until it finds the final answer or it gives up.
Chat Agent Flow
Here is the chat agent flow according to the LangChain implementation:
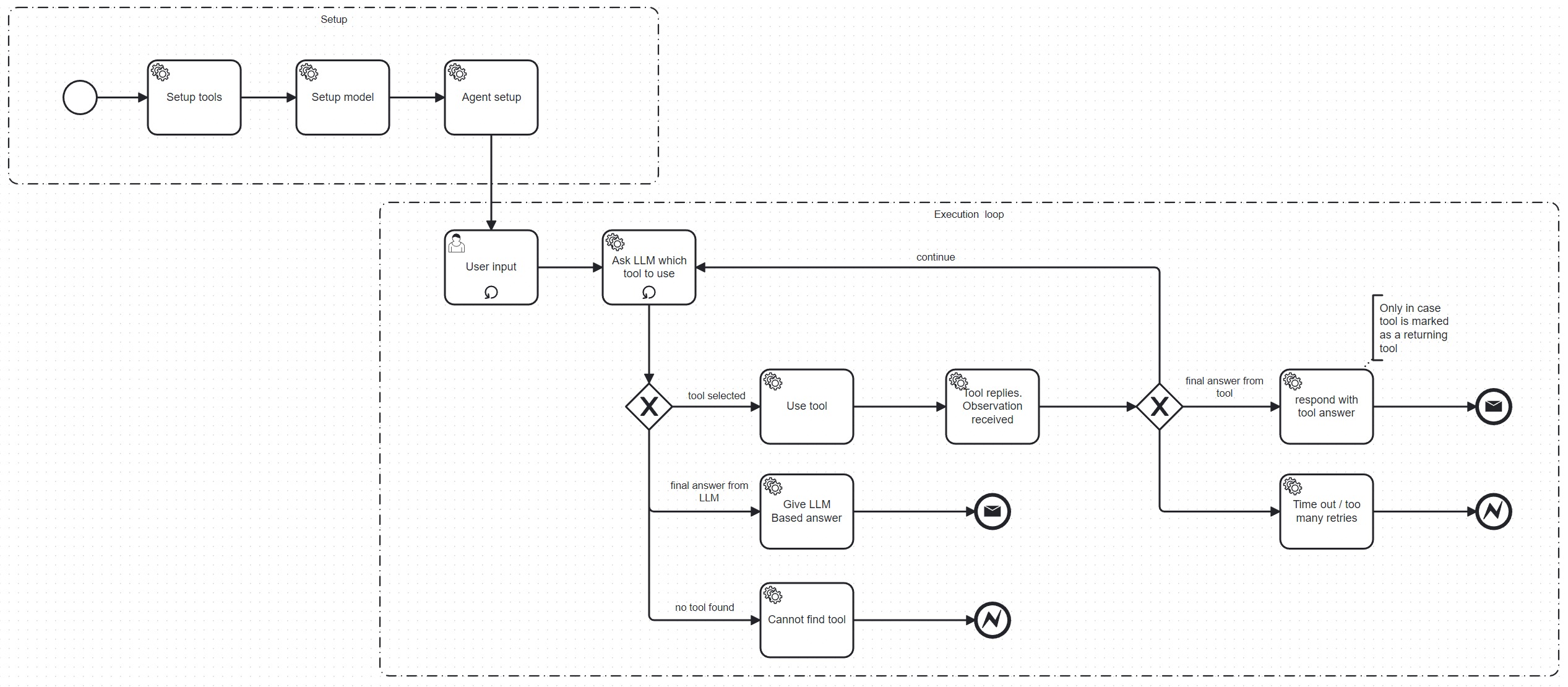
In a typical scenario of a web or command line application the flow can be divided in two parts:
- Setup flow: used to setup the main parts of the agent, including the tools and the LLM.
- Execution flow: consists of two loops. The outer loop processes the user input and the inner loop processes the agent interactions with the tools and the LLM.
Understanding the Execution Flow
The setup flow is typically just a sequential prelude to the main execution flow:
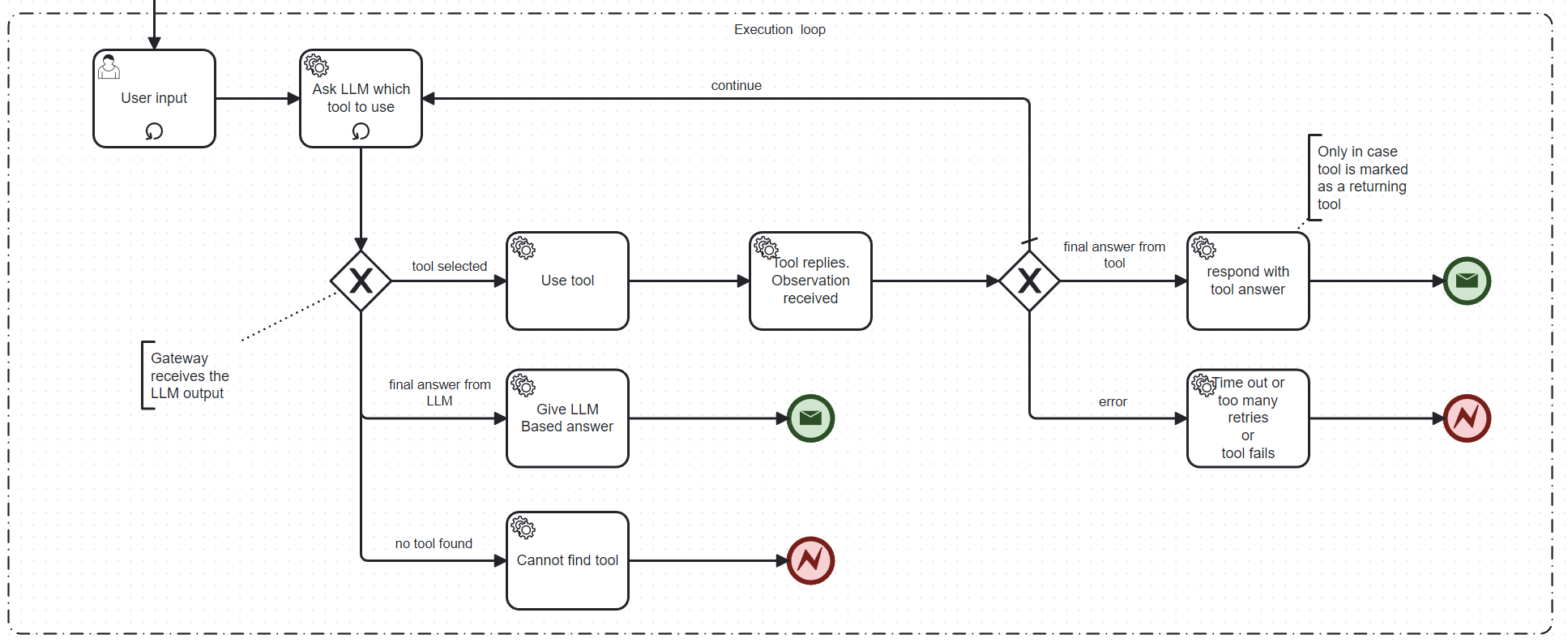
The flow executes the following steps:
- Accept the user input. The user input is typically a question entered via a web, mobile or command line UI.
- The agent starts its work: it asks the LLM which tool to use to give the final answer.
- At this stage, the first process gateway is reached. It has three outputs:
- Use tool: the LLM decided to use a specific tool. The flow continues below in “Tool replies”
- Give LLM Based answer: The LLM came up with the final answer
- Answer not understood: The LLM answer is inconclusive. The process exits here with an error. - Tool replies: The tool sends a message to the second gateway
- The second's workflow gateway is reached. It has three possible outcomes:
- normally the output of the tool is routed to the LLM. We return to the initial step of the agent loop.
- if the executed tool is marked as a “returning tool” the response from the tool is the final answer
- error condition happens: if the tool throws an error or a timeout occurs or the maximum amount of tries is reached the process exits with an error.
A Very Simple Wikipedia, DuckDuckGo, Arxiv Agent
We have built a very simple Agent that uses three built-in LangChain agents:
- Wikipedia (the beloved online encyclopedia)
- Arxiv (an online archive for scientific papers)
- DuckDuckGo (a privacy-oriented search engine)
We have used these three agents because they come out of the box in LangChain and also do not require any registration or paid subscriptions.
This command line application can be used to chat about different topics and ask questions like:
- Who is Donald Duck?
- What is the weather today in London?
- Who is Albert Einstein?
- Who will be the presidential candidates for the next presidential election in the US?
- Which were the most relevant publications about attention layers in neural networks in 2020?
Below is an excerpt of an interaction with the tool:
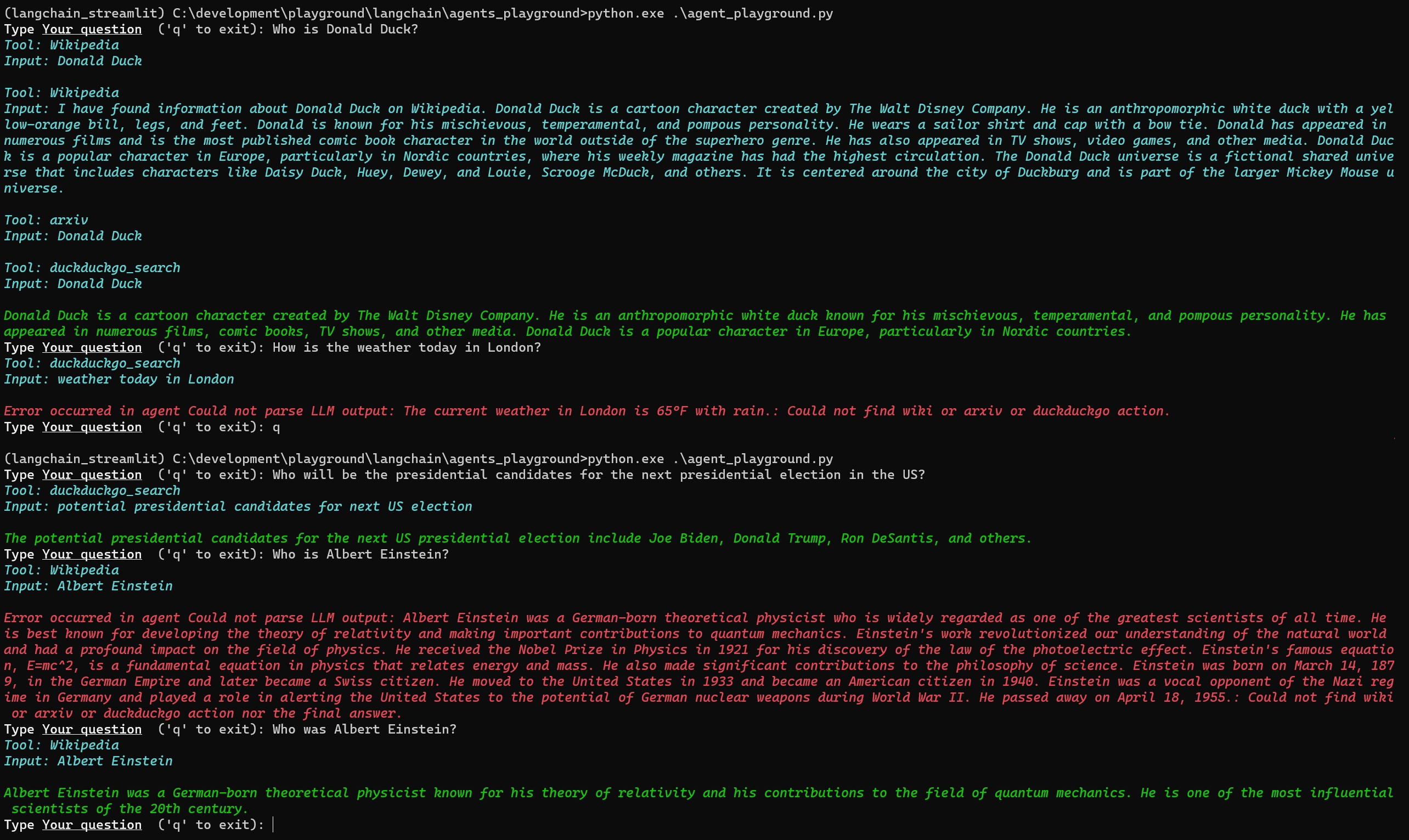
We have tried to colour-code the outputs of the tool:
- green: successful response
- red: error message with some explanation
- blue intermediate step; typically mentioning the tool and the question sent to the tool
Implementation
Our little chat application can be found in this GitHub repository:
GitHub - gilfernandes/agent_playground: Small demo project with a functional LangChain based agent.
Small demo project with a functional LangChain based agent. - GitHub - gilfernandes/agent_playground: Small demo…
The main agent code is in agent_playground.py
The agent is configured using this code:
class Config():
"""
Contains the configuration of the LLM.
"""
model = 'gpt-3.5-turbo-16k'
# model = 'gpt-4'
llm = ChatOpenAI(model=model, temperature=0)
cfg = Config()We are using gpt-3.5 API as you can see.
The agent is setup in this function below:
def create_agent_executor(cfg: Config, action_detector_func: callable, verbose: bool = False) -> AgentExecutor:
"""
Sets up the agent with three tools: wikipedia, arxiv, duckduckgo search
:param cfg The configuration with the LLM.
:param action_detector_func A more flexible implementation of the output parser, better at guessing the tool from the response.
:param verbose whether there will more output on the console or not.
"""
tools = load_tools(["wikipedia", "arxiv", "ddg-search"], llm=cfg.llm)
agent_executor: AgentExecutor = initialize_agent(
tools,
cfg.llm,
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=verbose
)
agent = agent_executor.agent
agent.output_parser = ExtendedChatOutputParser(action_detector_func)
return agent_executorAs you can see the three tools “Wikipedia”, “arxiv”, and "ddg-search” are loaded here and the agent executor is setup here using the CHAT_ZERO_SHOT_REACT_DESCRIPTIONtype.
You may also notice that we have added a custom output parser. The output parser is tasked with parsing the output coming from the LLM. We wanted to have a more flexible implementation of the output parser that could better detect which tool to use — mainly because of a good number of misses we were getting during testing. This is the implementation of the tool which can be found in the file: chat_output_parser.py.
This is the custom implementation of the output parser:
class ExtendedChatOutputParser(ChatOutputParser):
action_detector_func: Callable
def __init__(self, action_detector_func: Callable):
super().__init__(action_detector_func=action_detector_func)
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
includes_answer = FINAL_ANSWER_ACTION in text
try:
action = self.action_detector_func(text)
response = json.loads(action.strip())
includes_action = "action" in response
if includes_answer and includes_action:
raise OutputParserException(
"Parsing LLM output produced a final answer "
f"and a parse-able action: {text}"
)
print(get_colored_text(f"Tool: {response['action']}", "blue"))
print(get_colored_text(f"Input: {response['action_input']}", "blue"))
print()
return AgentAction(
response["action"], response.get("action_input", {}), text
)
except Exception as e:
if not includes_answer:
raise OutputParserException(f"Could not parse LLM output: {text}: {str(e)}")
return AgentFinish(
{"output": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text
)This implementation allows to specify your custom function for detecting the action — or in other words — which tool to use next.
The function we wrote to detect the next from the LLM input can be found again in agent_playground.py:
def action_detector_func(text):
"""
Method which tries to better understand the output of the LLM.
:param text: the text coming from the LLM response.
:return a json string with the name of the tool to query next and the input to that tool.
"""
splits = text.split("```")
if len(splits) > 1:
# Original implementation + json snippet removal
return re.sub(r"^json", "", splits[1])
else:
lower_text = text.lower()
tool_tokens = ["wiki", "arxiv", "duckduckgo"]
token_tool_mapping = {
"wiki": "Wikipedia",
"arxiv": "arxiv",
"duckduckgo": "duckduckgo_search"
}
for token in tool_tokens:
if token in lower_text:
return json.dumps({
'action': token_tool_mapping[token],
'action_input': text
})
raise OutputParserException('Could not find wiki or arxiv or duckduckgo action nor the final answer.')In this function, we do not only look for the expected JSON output but also for words which might indicate to use of the next tool.
One of the problems of using LLMs is that they are somehow unpredictable and express themselves in unexpected ways, so this function is just an attempt to capture in a more flexible way the message the LLM wants to convey.
Observations
We have noticed that LangChain used a special prompt to query the LLM about the how to react to an input. The prompt used in this library is this one:
Answer the following questions as best you can. You have access to the following tools:
Wikipedia: A wrapper around Wikipedia. Useful for when you need to answer general questions about people, places, companies, facts, historical events, or other subjects. Input should be a search query.
arxiv: A wrapper around Arxiv.org Useful for when you need to answer questions about Physics, Mathematics, Computer Science, Quantitative Biology, Quantitative Finance, Statistics, Electrical Engineering, and Economics from scientific articles on arxiv.org. Input should be a search query.
duckduckgo_search: A wrapper around DuckDuckGo Search. Useful for when you need to answer questions about current events. Input should be a search query.
The way you use the tools is by specifying a json blob.
Specifically, this json should have a `action` key (with the name of the tool to use) and a `action_input` key (with the input to the tool going here).
The only values that should be in the "action" field are: Wikipedia, arxiv, duckduckgo_search
The $JSON_BLOB should only contain a SINGLE action, do NOT return a list of multiple actions. Here is an example of a valid $JSON_BLOB:
```
{
"action": $TOOL_NAME,
"action_input": $INPUT\n}
```
ALWAYS use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action:
```
$JSON_BLOB
```
Observation: the result of the action
... (this Thought/Action/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin! Reminder to always use the exact characters `Final Answer` when responding.'The prompt is sent via system message to the LLM together with the question or observations from tool responses.
We think it is interesting to know how you instruct the LLM to behave in this scenario.
Final Thoughts
In this story, we tried to describe how a simple chat agent works and tried to understand the inner mechanics of the chat agent. You can enhance the power of Large Language Models with extra tools which are able to expand the knowledge of LLMs to areas not usually accessible to them. LLMs are not trained on older knowledge base but with openly available information. If you want to access cutting-edge news together with LLMs, agents are a good option to start with.
There is a lot more you can do with agents, like letting them engage in adversarial scenarios or against code bases, but we will be looking at those scenarios in our upcoming stories.